Xây dựng hệ thống gợi ý bài viết cho ... website Viblo
Xây dựng hệ thống gợi ý bài viết cho … website Viblo
-
Hệ gợi ý (Hệ khuyến nghị) hay Recommender System (hoặc Recommendation System) hiện nay là một trong những vấn đề được các công ty hay các trang thương mại điện tử rất quan tâm. Ngày nay, trên thế giới nói chung và tại Việt Nam nói riêng, các hệ thống recommender system đã trở thành một xu hướng không thể thiếu trong thương mai điện tử. Mục đích của nó là hỗ trợ người dùng tìm kiếm được đúng các thông tin cần thiết, dự đoán sở thích hay xếp hạng mà ngươì dùng có thể dành cho một sản phẩm nào đó mà khách hàng xem xét tới trong quá khứ. Từ đó, gợi ý cho người dùng các sản phẩm liên quan. Việc thực hiện tính toán được xây dựng dựa trên các thuật toán Học máy (Machine Learning), đưa ra các dự đoán tốt nhất về sản phẩm mà người dùng có thể thích, giúp tối ưu hóa doanh thu, tăng tín nhiệm, … Cải thiện trải nghiệm người dùng, tăng hiệu năng hoạt động bằng tự động hóa, biến khách hàng tiềm năng trở thành khách hàng thật.
-
Nhìn chung hệ gợi ý được xây dựng với 2 cách tiếp cận chủ đạo là:
Content-BasedvàColaborative Filtering. Mình sẽ không đi sâu vào phân tích từng cách tiếp cận trên, các bạn có thể tham khảo thêm tại website machinelearningcoban.com - từ bài 23 đến bài 26. Mình nghĩ khá chi tiết và cụ thể rồi nên sẽ không đề cập lại, chỉ hơi nhiều toán một chút thôi :D -
Đây cũng là bài blog đầu tiên của mình trên Viblo, và chủ đề mình muốn viết đó là: xây dựng một hệ thống gợi ý cơ bản cho website
Viblo. Các bạn cũng có thể tham khảo source code tại đây. Nếu có sai sót gì trong bài viết, các bạn vui lòng comment bên dưới hoặc liên hệ về mailphan.huy.hoang@framgia.comnhé. Không dài dòng nữa, bắt đầu thôi! :D -
Github Link: https://github.com/huyhoang17/LDA_Viblo_Recommender_System
-
Các bước tiến hành
- Chuẩn bị dữ liệu
- Tiền xử lí dữ liệu
- Mô hình hóa hệ gợi ý LDA
Chuẩn bị dữ liệu:
- Về dữ liệu các bài viết trên viblo, các bạn có thể lấy bằng cách truy cập API của Viblo:
https://viblo.asia/api/posts
https://viblo.asia/api/posts?page=1
https://viblo.asia/api/posts?page=100
...
hoặc để truy cập API của 1 post, các bạn truy cập vào link với format như sau:
https://viblo.asia/api/posts/<slug>
- Với slug là 1 chuỗi kí tự random, có thể dễ dàng lấy được trên url của từng bài viết:
https://viblo.asia/p/installing-apache-php-mysql-on-ubuntu-1804-GrLZDXBBZk0
# <slug> = GrLZDXBBZk0
https://viblo.asia/api/posts/GrLZDXBBZk0
- Có 1 điểm chú ý là các bạn không nên gửi request liên tục lên API, rất có thể sẽ bị chặn truy cập và dẫn đến xảy ra lỗi khi chạy code. Cách đơn giản nhất cách bạn có thể thực hiện là dừng lại 1 lúc trước khi tiếp tục thực hiện request đến page tiếp theo
import time
time.sleep(0.1)
Xử lí dữ liệu
-
Xử lí dữ liệu là một trong những bước quan trọng nhất khi thực hiện bất kì 1 project liên quan đến
Machine Learningnào. Dữ liệu có “tốt” thì mới mong mô hình có thể “tốt” được, không cũng chỉ"Garbage In, Garbage Out"mà thôi! -
Trường
contentstrong dữ liệu mình lấy từ API về được viết dưới dạngmarkdown(một ngôn ngữ định dạng văn bản tương tự HTML, nhưng đơn giản và dễ sử dụng hơn nhiều), nên công đoạn đầu tiên đó là xử lí đống dữ liệu markdown này trước đã:
# Nghề hot hiện nay là thiết kế website và biết làm SEO\nNhững năm gần đây, nhu cầu tuyển dụng nhân sự vừa có khả năng **[thiết kế web](http://cuthtmlcss.com/dich-vu/thiet-ke-website/)**, vừa có thể làm **seo** ngày càng lớn. Vì các doanh nghiệp bắt đầu nhận ra lợi ích của việc bán hàng, kinh doanh hiệu quả bằng chính website của mình. Cuộc chiến tranh giành thứ hạng trên google chưa bao giờ nóng như lúc này, khi website của bạn ở trang nhất google, đồng nghĩa với cơ hội marketing sản phẩm tới khách hàng lớn hơn bao giờ hết. Để thực hiện điều này, đòi hỏi các công ty, doanh nghiệp phải có một đội ngũ **lập trình viên** và seo riêng biệt, đặc biệt là kiếm người vừa có đồng thời hai khả năng trên không phải là điều dễ dàng. Do đó mà mức lương cho nhân viên **[seo website lên top google](http://webmastershaven.net/vi-sao-phai-seo-website-len-top-google/)** luôn ở mức khá, điều này khiến cho nghề thiết kế website và seo web được đông đảo bạn trẻ quan tâm. Tuy nhiên, **nghề hot hiện nay** cũng đòi hỏi người làm phải thực sự giỏi, chịu áp lực công việc cao.\n\n\n## Học thiết kế website không lo thất nghiệp\n\nNếu như trước đây, các doanh nghiệp chỉ **thiết kế web giới thiệu** theo kiểu trưng bày cho có, thì giờ đây họ bắt đầu quan tâm nhiều hơn đến giao diện, tính năng, và thông tin sản phẩm phải luôn được cập nhật. Những việc này thì không thể giao phó hoàn toàn cho bên các đơn vị, **công ty thiết kế web**, vì chi phí sẽ đội lên rất cao, mỗi lần yêu cầu nhờ support là một lần khó, đó còn là chưa kể thuê thêm một công ty chuyên về seo. Rõ ràng, họ cần một nhân viên thiết kế web, [seo](https://vi.wikipedia.org/wiki/T%E1%BB%91i_%C6%B0u_h%C3%B3a_c%C3%B4ng_c%E1%BB%A5_t%C3%ACm_ki%E1%BA%BFm) chuyên biệt.\nXem thêm: [thiết kế website chuyên nghiệp cần gì?](https://viblo.asia/p/thiet-ke-website-chuyen-nghiep-can-gi-OeVKBYpE5kW)\n## Bạn cũng nên học thêm kiến thức seo \nCông việc của những nhân viên này là sao tối ưu trang web, cập nhật tin tức, bài viết, giới thiệu sản phẩm, dịch vụ mới của công ty. Thường xuyên kiểm tra, cập nhật, hoặc thay đổi những tính năng của website sao cho khách hàng dễ sử dụng nhất. Chẳng hạn như khung đặt hàng, bạn cần phải thiết kế, chỉnh sửa làm sao cho khách hàng cảm thấy thoải mái, không thể bắt họ nhập quá nhiều thông tin, hoặc thao tác liên tục. Nếu để họ bực mình chắc chắn công ty của bạn sẽ mất một đơn hàng, mà nhiều người như thế thì doanh số sẽ bị giảm nghiêm trọng. Hoặc chỗ hình ảnh sản phẩm, bạn phải biết up hình sao cho cân đối dễ nhìn, thông tin đầy đủ, giúp khách hàng có thể cảm nhận rõ nét về sản phẩm của công ty nhất....Thỉnh thoảng website của công ty có thể bị ai đó chơi xấu, bạn cũng phải biết khắc phục ngay lập tức. Bởi vì website là bộ mặt của doanh nghiệp, giúp quảng bá sản phẩm, dịch vụ của doanh nghiệp tới khách hàng 24h mỗi ngày, 365 ngày trong năm, nên nếu website bị rớt có nghĩa là doanh nghiệp phải tạm đóng cửa, thiệt hại là không thể đo đếm được. Rõ ràng **nghề hot hiện nay** này đòi hỏi người lao động phải có trình độ chuyên môn cao, bản lĩnh, và sự kiên trì.\n\n dấu ngoặc tròn
...
mà không được tổ chức dưới dạng các thẻ như HTML, mà là các kí tự đặc biệt hay punctuation
- Một giải pháp được đưa ra đó là chuyển dữ liệu từ định dạng markdown sang HTML rồi tiếp tục xử lí. Vì có khá nhiều các thư viện đã hỗ trợ việc xử lí với HTML, kết quả khá tốt. Thư viện mình dùng để xử lí markdown là mistune:
pip install mistune
def markdown_to_text(markdown_string, parser="html.parser",
tags=['pre', 'code', 'a', 'img', 'i']):
markdown = mistune.Markdown()
html = markdown(markdown_string)
soup = BeautifulSoup(html, parser)
# remove code snippets
text = preprocessing_tags(soup, tags)
text = remove_links_content(text)
text = remove_emails(text)
text = remove_punctuation(text)
text = text.replace('\n', ' ')
text = remove_numeric(text)
text = remove_multiple_space(text)
text = text.lower().strip()
text = ViTokenizer.tokenize(text)
text = remove_stopwords(text, stopwords=stopwords)
return text
xem chi tiết tại: utils.py
-
Sau khi đã chuyển sang HTML, các kí tự đặc biệt bên markdown đã được chuyển sang các thẻ bên HTML, ví dụ:
<code>, <pre>, <a>, <img>, <i>, .. - Tiếp đến loại bỏ các thành phần sau, vì không mang nhiều ý nghĩa và gây nhiễu khi huấn luyện mô hình. Sau đây là 1 số bước mình xử lí với trường
contents:- Dùng thư viện
bs4đểparseđoạn context vừa chuyển sang HTML bên trên. Lí do sử dụng bs4 vì thư viện này hỗ trợ khá tốt khi xử lí với thẻ HTML, 1 vài thư viện khác các bạn có thể tham khảo như:lxml, .. - Bỏ các thẻ và phần nội dung nằm giữa các thẻ đặc biệt như:
<code>, <pre>, vì đây là các thẻ được dùng để bọc các đoạn code, command, .. nên không có nhiều ý nghĩa - Loại bỏ các đường dẫn (link)
- Loại bỏ các email
- Loại bỏ các kí tự đặc biệt
- Thay thế các kí tự khoảng trắng (bao gồm
\n, \tthành' 'hay loại bỏ nhiều kí tự khoảng trắng liền nhau về' 'luôn) - Loại bỏ số
- Loại bỏ stopwords (là các từ xuất hiện nhiều trong văn nói, văn viết nhưng không mang nhiều ý nghĩa, ví dụ: rằng, thì, là, mà, … Về danh sách các stopwords của tiếng Việt, các bạn có thể tham khảo ơ đây: Stopwords Vietnamese - Cảm ơn tác giả Le Van Duyet :D
- Dùng thư viện
-
Ở đây có một chú ý là tiếng Việt bao gồm nhiều từ ghép, được ghép bởi >=2 từ trở lên, đứng riêng lẻ từng từ một thì không có ý nghĩa, nếu xử lí bằng cách đơn giản là phân cách các từ tại các dấu
spacethì có thể khiến cho việc huấn luyện mô hình về sau gặp những sai sót hoặc kết quả không thực sự tốt. Ở đây mình có sử dụng một thư viện là PyVi, hỗ trợ khá tốt vấn đề vềtokenizevàpostaggingvới tiếng Việt, các bạn có thể tham khảo thử. Cảm ơn tác giả trungtv :D - Kết quả sau khi đã tiến hành xử lí theo các bước bên trên
nghề hot thiết_kế website seo nhu_cầu tuyển_dụng nhân_sự khả_năng seo doanh_nghiệp lợi_ích hàng kinh_doanh hiệu_quả website chiến_tranh_giành thứ_hạng google nóng website trang google đồng_nghĩa marketing sản_phẩm khách_hàng đòi_hỏi công_ty doanh_nghiệp đội_ngũ lập_trình_viên seo riêng_biệt kiếm hai khả_năng dễ_dàng lương nhân_viên nghề thiết_kế website seo web đông_đảo trẻ nghề hot đòi_hỏi người_làm giỏi áp_lực công_việc cao_học thiết_kế website lo thất_nghiệp doanh_nghiệp thiết_kế web giới_thiệu kiểu trưng_bày giao_diện tính_năng thông_tin sản_phẩm cập_nhật giao_phó công_ty thiết_kế web chi_phí đội support thuê công_ty chuyên seo rõ_ràng nhân_viên thiết_kế web chuyên_biệt học kiến_thức seo công_việc nhân_viên tối_ưu trang_web cập_nhật tin_tức viết giới_thiệu sản_phẩm dịch_vụ công_ty thường_xuyên kiểm_tra cập_nhật tính_năng website khách_hàng chẳng_hạn khung đặt_hàng thiết_kế chỉnh_sửa khách_hàng thoải_mái bắt nhập thông_tin thao_tác liên_tục bực_mình công_ty đơn hàng doanh_số nghiêm_trọng chỗ hình_ảnh sản_phẩm up hình cân_đối thông_tin đầy_đủ giúp khách_hàng cảm_nhận nét sản_phẩm công_ty nhấtthỉnh thoảng website công_ty chơi_xấu khắc_phục lập_tức website bộ_mặt doanh_nghiệp giúp quảng_bá sản_phẩm dịch_vụ doanh_nghiệp khách_hàng h website rớt nghĩa_là doanh_nghiệp tạm đóng_cửa thiệt_hại đo_đếm rõ_ràng nghề hot đòi_hỏi lao_động trình_độ chuyên_môn bản_lĩnh kiên_trì mảng nhân_viên đa_nhiệm thiết_kế web seo nhiệm_vụ quản_trị website đăng hình viết sản_phẩm website khách_hàng seo web tức_là khóa keyword sản_phẩm dịch_vụ top google công_việc hề đơn_giản hôm_nay top google ngày_mai cuộc_chiến khốc_liệt khoan_nhượng doanh_nghiệp ảo_tưởng sức_mạnh thuê top google công_việc seo đội bắt nhân_viên chẳng một_mình chống mafia thu_nhập nghề thiết_kế web seo thách_thức đòi_hỏi chuyên_môn bù lương nhân_viên kiểu đãi_ngộ hậu_hĩnh học thiết_kế website học_các ngôn_ngữ lập_trình ngôn_ngữ lập_trình lập_trình website lập_trình phần_mềm ứng_dụng lập_trình app android học_các ngôn_ngữ lập_trình cơ_bản làm_quen dần thế_giới lập_trình_như ngôn_ngữ lập_trình c css c java javascript php học lập_trình niềm đam_mê yêu học ngành học đừng phí tương_tự nghề lập_trình_viên nghề seo đòi_hỏi chuyên_môn kỹ_thuật vững_chắc kiến_thức đa ngành đa_hệ công_việc seo đơn_giản quanh_quẩn mấy kế_hoạch seo tổng_thể lập khóa viết content chuẩn seo chuẩn hàng đi link thành_thạo chuyên_gia hề đơn_giản kinh_nghiệm học khóa seo công_ty thực_tập lên_tay seo dự_án tổng_quan thị_trường việc_làm học thiết_kế web seo web việc_làm bao nghề web seo nghề hot công_ty công_ty có_nhân_sự quản_trị website thuê công_ty dịch_vụ học thực_hành tất_yếu nhân_viên pro cuộc_sống nhấn_mạnh làm_việc chú_tâm ông_bà câu nghệ_tinh thân vinh nghề thiết_kế website seo web học học tới_chốn được_việc đứng sinh tâm chán_nản đứng núi trông_núi tâm_tưởng thành_công
- Có thể thấy là thư viện
PyViđã xử lí khá tốt đối với các từ ghép, ví dụ:lập_trình_viên, kinh_nghiệm, nhân_viên, thiết_kế, ..Tuy nhiên cũng có 1 vài chỗ chưa thực sự chuẩn lắm, ví dụ:có_nhân_sự, chiến_tranh_giànhNhưng nhìn chung kết quả đem lại khá tốt và mình khá hài lòng với kết quả như vậy :D
Mô hình hóa với thuật toán LDA
- Thuật toán LDA (Latent Dirichlet Allocation) là một trong những phương pháp Topic Modeling được sử dụng nhiều nhất. LDA miêu tả các văn bản như là sự pha trộn của các topics (bao gồm các từ * trọng số của các từ đó) với các xác suất nhất định. Mô hình này gần giống với phương pháp pLSA (nâng cao hơn của thuật toán LSA), ngoại trừ điểm cơ bản nhất đó là các phân bố
topictrong LDA được giả định theo phân bố Dirichlet thưa (hay sparse Dirichlet), với mục đích biểu thị rằng các đoạn văn bản (document) được biểu diễn bằng 1 số cáctopicvà cáctopicđó lại được biểu diễn bằng 1 tập nhỏ các từ (với trọng số ứng với từng từ giảm dần)
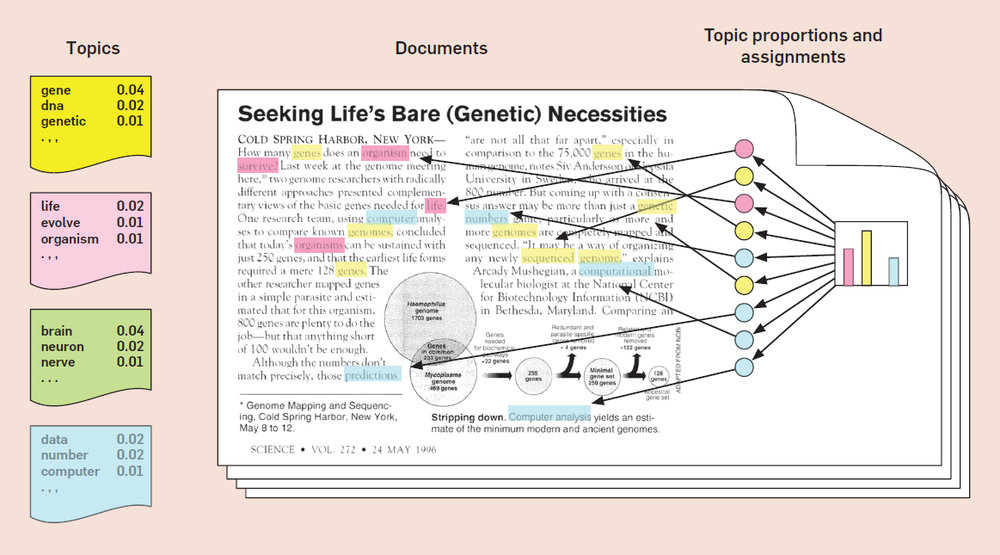
- Để mọi người dễ hình dung hơn, ta đi đến 1 ví dụ đơn giản sau. Giả sử bạn có 1 tập các đoạn văn bản (documents) như sau:
- Machine Learning và AI trong thời gian qua đã đạt được các thành tựu vô cùng đáng kinh ngạc
- Blockchain - từ công nghệ tiền ảo đến ứng dụng tương lại
- Tác hại kinh hoàng của game online với giới trẻ hiện nay
- Mâu thuẫn khi chơi game, nam sinh giết hại bạn của mình cho bõ tức
- Trí tuệ nhân tạo OpenAI chính thức đánh bại 5 game thủ chuyên nghiệp giỏi nhất thế giới
-
Với LDA, giả sử hiện tại bạn quy định sẽ có 2 topic (chưa có tên cụ thể) cần được “phân phối” vào các văn bản cụ thể, LDA sẽ cho ra các kết quả như sau
- Văn bản 1 và 2 được phân loại vào topic 1
- Văn bản 3 và 4 được phân loại vào topic 2
-
Văn bản 5 được phân loại như sau: 80% topic 1, 20% topic 2
- Topic 1 được quy định bằng các trọng số của các từ liên quan (cũng là các từ có trọng số lớn nhất) như:
30% về machine_learning + 30% về AI + 20% về block_chain + 10% về mã_hóa + 10% về bảo_mật + ...Từ đó, ta có thể thấy topic 1 liên quan khá nhiều đếnCông nghệ - Topic 2 được quy định như sau:
30% về game + 20% về giới_trẻ + 20% về mâu_thuẫn + 20% về tác_hại + 10% về online ...Từ đó, có thể thấy topic 2 nói về các vấn đề liên quan đếngame
-
Vậy câu hỏi đặt ra là: làm sao LDA có thể thực hiện được việc phân phối các topic và các từ thuộc từng topic với từng xác suất chi tiết như vậy?
- Giả sử hiện tại bạn có 1 tập hợp các đoạn văn bản (documents). Việc đầu tiên bạn phải làm là xác định số K
topicsđể tiến hành phân phối sau này, và việc đó được thực hiện như sau:- Ứng với mỗi văn bản, ngẫu nhiên gán các từ trong đoạn văn bản đó với 1 trong K
topics - Với mỗi văn bản
d:- Với mỗi từ
wtrong văn bảnd:- Với mỗi topic
t, ra tính toán 2 thông số: 1 làp(topic t | document d)vàp(word w | topic t). Tiến hành gán lại từwvới 1topicmới với xác suấtp(topic t | document d) * p(word w | topic t)
- Với mỗi topic
- Với mỗi từ
- Sau khi lặp lại bước trên 1 số lần nhất định, việc phân phối giữa
document-topicvàtopic-wordđã đạt tới trạng thái đủ tốt. Từ đó, ta có thể sử dụng mô hình để ước lượng phân phốitopiccủa mỗi văn bản (document) và từ (word) với mỗitopic
- Ứng với mỗi văn bản, ngẫu nhiên gán các từ trong đoạn văn bản đó với 1 trong K
- Cụ thể hơn:
- Xác định số K
topicsđể tiến hành phân phối sau này, số K là gì và việc chọn số K bao nhiêu là ổn, mình sẽ đề cập kĩ hơn bên dưới. - Gán
TẠMmỗi từ trong đoạn văn bản với 1topicnhất định. Việc này thực hiện sau khi đã bỏ đi các từstopwords. Lưu ý là cùng 1 từ nhưng hoàn toàn có thể thuộc cáctopickhác nhau. - Kiểm tra và tiến hành cập nhật việc gán từ cho mỗi
topic, dựa trên 2 tiêu chí:- Độ phổ biến của
wordđó trong cáctopic - Độ phổ biến của
topictrong cácdocuments
- Độ phổ biến của
- Xác định số K
-
Ở đây, mình có sử dụng thư viện
Gensim, là một trong những thư viện hỗ trợ tốt và đa dạng các bài toán liên quan đến Topic Modeling như:LSA, LDAhay các bài toán liên quan đến Word Embedding như:Word2Vec, Doc2Vec, các bạn quan tâm có thể tham khảo thêm tại phần Tutorial của Gensim -
Nhìn chung, khi sử dụng Gensim với bài toán LDA, có một số điểm mà các bạn cần chú ý khi định nghĩa:
dictionary: mapping giữa index và các từ. Ví dụ:{0: 'computer', 1: 'human', 2: 'interface', 3: 'response', 4: 'survey', 5: 'system', 6: 'time', 7: 'user', 8: 'eps', 9: 'trees', 10: 'graph', 11: 'minors'}corpus: list chứa bộ các tuple theo định dạng(index, word_frequency). Ví dụ:[(0, 1), (1, 2), (2, 1)]tương ứng với từ tại index 0 xuất hiện 1 lần, từ tại index 1 xuất hiện 2 lần, từ tại index 2 xuất hiện 1 lần trong đoạn văn bản đó. Index tính theo tổng số từ (không lặp lại) trong toàn bộ tập văn bản.
- Một điểm chú ý nữa đó là
gensimhỗ trợ việcfetchdữ liệu theoiterable objectthay vì là 1 mảng (list hoặc numpy array). Do đó, bạn không cần phải tạo 1 list chứa 1.000.000 văn bản (rất tốnRAM) rồi mới đưa vào model, đơn giản là viết code return vềgeneratortrong python, sau đây là 1 số đoạn code ví dụ:
# sentences cũng được fetch theo generator object
def make_texts_corpus(sentences):
for sentence in sentences:
yield simple_preprocess(sentence, deacc=True)
class StreamCorpus(object):
def __init__(self, sentences, dictionary, clip_docs=None):
"""
Parse the first `clip_docs` documents
Yield each document in turn, as a list of tokens.
"""
self.sentences = sentences
self.dictionary = dictionary
self.clip_docs = clip_docs
def __iter__(self):
for tokens in itertools.islice(
make_texts_corpus(self.sentences), self.clip_docs):
yield self.dictionary.doc2bow(tokens)
def __len__(self):
return self.clip_docs
các bạn đọc thêm tại đây
- LDA model
import gensim
lda_model = gensim.models.LdaModel(corpus, num_topics=64, id2word=id2word, passes=5, chunksize=100, random_state=42, alpha=1e-2, eta=0.5e-2, minimum_probability=0.0), per_word_topics=True)
ở đây mình chọn số lượng topic là 64 (chính là số K bên trên), đây cũng sẽ là số quy định vector đầu ra ứng với ma trận documents x topics, thể hiện việc phân bố topic ứng với từng document, mỗi document sẽ được biểu diễn bằng vector 64 chiều.
-
Vậy câu hỏi đặt ra là: số
topicquy định bao nhiêu là tốt, liệu mình lấy 10 hay 1000topicscó được không? Lúc đó, 1 giá trị được quy định gọi làCoherence Value,Coherence Valuecàng cao thì càng tốt. Các bạn đọc thêm vềCorehenre Valuetại đây -
Kết quả một số
topicthu được sau khi chạy mô hình
lda_model.print_topics(-1)
INFO : topic #56 (0.010): 0.127*"javascript" + 0.095*"html" + 0.052*"jquery" + 0.047*"thu_vien" + 0.047*"template" + 0.039*"dom" + 0.036*"js" + 0.030*"ajax" + 0.023*"angular" + 0.019*"css"
INFO : topic #23 (0.010): 0.113*"trang" + 0.109*"web" + 0.082*"trang_web" + 0.063*"website" + 0.055*"trinh_duyet" + 0.043*"angularjs" + 0.033*"url" + 0.028*"link" + 0.025*"html" + 0.024*"page"
INFO : topic #31 (0.010): 0.101*"team" + 0.072*"agile" + 0.058*"product" + 0.051*"release" + 0.050*"master" + 0.044*"scrum" + 0.033*"thanh_vien" + 0.025*"owner" + 0.021*"tables" + 0.016*"mo_hinh"
INFO : topic #3 (0.010): 0.135*"lenh" + 0.064*"thu_muc" + 0.054*"dong" + 0.027*"mac_đinh" + 0.026*"cau_lenh" + 0.023*"thiet_lap" + 0.020*"phien_ban" + 0.015*"cau_hinh" + 0.015*"đuong_dan" + 0.014*"tu_đong"
INFO : topic #50 (0.010): 0.149*"rails" + 0.096*"gem" + 0.049*"ruby" + 0.035*"redis" + 0.028*"cluster" + 0.028*"job" + 0.022*"chat" + 0.017*"gemfile" + 0.016*"on" + 0.014*"config"
INFO : topic #53 (0.010): 0.050*"thiet_ke" + 0.039*"hang" + 0.021*"unity" + 0.020*"san_pham" + 0.015*"khach_hang" + 0.014*"bao_cao" + 0.014*"yeu_to" + 0.013*"dich_vu" + 0.012*"cong_ty" + 0.012*"mua"
INFO : topic #0 (0.010): 0.134*"ui" + 0.091*"domain" + 0.083*"mobile" + 0.069*"native" + 0.053*"platform" + 0.045*"virtual" + 0.036*"objectivec" + 0.034*"chain" + 0.028*"markup" + 0.023*"nen_tang"
INFO : topic #44 (0.010): 0.325*"app" + 0.028*"store" + 0.026*"tutorial" + 0.024*"play" + 0.018*"developer" + 0.017*"changes" + 0.016*"apps" + 0.016*"qr" + 0.016*"devices" + 0.014*"book"
INFO : topic #36 (0.010): 0.055*"luu_tru" + 0.048*"database" + 0.047*"ghi" + 0.046*"co_so" + 0.039*"luu" + 0.037*"truong" + 0.032*"thao_tac" + 0.026*"xoa" + 0.026*"bang" + 0.024*"kieu"
INFO : topic #63 (0.010): 0.176*"model" + 0.119*"controller" + 0.093*"user" + 0.083*"view" + 0.038*"mvc" + 0.024*"aspnet" + 0.020*"active" + 0.019*"route" + 0.017*"framework" + 0.016*"tuong_ung"
INFO : topic #57 (0.010): 0.164*"android" + 0.067*"google" + 0.059*"activity" + 0.034*"api" + 0.033*"sdk" + 0.032*"thu_vien" + 0.026*"map" + 0.026*"ban_đo" + 0.024*"studio" + 0.021*"fragment"
INFO : topic #26 (0.010): 0.058*"to" + 0.037*"and" + 0.036*"is" + 0.034*"of" + 0.030*"in" + 0.022*"you" + 0.021*"for" + 0.020*"it" + 0.018*"that" + 0.018*"this"
INFO : topic #52 (0.010): 0.118*"tap_tin" + 0.098*"tai" + 0.070*"eclipse" + 0.049*"nen" + 0.035*"ma" + 0.031*"spring" + 0.028*"download" + 0.028*"đinh_dang" + 0.024*"cau_hinh" + 0.022*"giai"
INFO : topic #10 (0.010): 0.047*"click" + 0.035*"nut" + 0.026*"button" + 0.024*"man_hinh" + 0.024*"nhap" + 0.020*"nhan" + 0.016*"menu" + 0.015*"add" + 0.014*"chuot" + 0.014*"tab"
INFO : topic #27 (0.010): 0.127*"function" + 0.069*"string" + 0.053*"true" + 0.051*"null" + 0.043*"false" + 0.043*"set" + 0.036*"object" + 0.036*"property" + 0.033*"var" + 0.027*"return"
...
- Sau khi thực hiện training model, các bạn nhớ thực hiện việc lưu lại model nhé:
# save corpus
gensim.corpora.MmCorpus.serialize(PATH_CORPUS, corpus)
# save dictionary
gensim.corpora.Dictionary.dictionary.save(PATH_DICTIONARY)
# save LDA model
gensim.models.LdaModel.save(PATH_LDA_MODEL)
- sau đó các bạn thực hiện việc tính toán ma trận
documents x topicsvà lưu lại ma trận bằng đoạn code sau:
import numpy as np
from sklearn.externals import joblib
# class method
def documents_topic_distribution(self):
doc_topic_dist = np.array(
[[tup[1] for tup in lst] for lst in self.lda_model[self.corpus]]
)
# save documents-topics matrix
joblib.dump(doc_topic_dist, PATH_DOC_TOPIC_DIST)
return doc_topic_dist
- Khi có một bài viết mới trên viblo, công việc đầu tiên thực hiện sẽ là
parsedữ liệu dạng markdown tại trườngcontentnhư bên trên. Sau đó, sử dụngdictionaryvàLDA modelđã train và lưu lại để thu được vectordocument_dist, ứng với phân bố các topic của document đó. Code minh họa:
# class method
def transform(self, sentence):
"""
:param document: preprocessed document
"""
document_corpus = next(make_texts_corpus([sentence]))
corpus = self.id2word.doc2bow(document_corpus)
document_dist = np.array(
[tup[1] for tup in self.lda_model.get_document_topics(bow=corpus)]
)
return corpus, document_dist
- Sau đó tiến hành so sánh độ tương tự với từng
sampletrong ma trậndocuments x topicsđã lưu bên trên. Metric mình sử dụng ở đây làJensen Shannon, các bạn có thể đọc thêm tại đây. Code minh họa:
from scipy.stats import entropy
def jensen_shannon(query, matrix):
p = query[None, :].T
q = matrix.T
m = 0.5 * (p + q)
return np.sqrt(0.5 * (entropy(p, m) + entropy(q, m)))
- và thực hiện việc sắp xếp các giá trị đó, khoảng cách càng nhỏ chứng tỏ sự tương đồng phân bố
topicsgiữa 2documentscàng cao. Ở đây, mình lấyk=10ứng với 10documentstương đồng nhất. Code minh họa:
def get_most_similar_documents(query, matrix, k=10):
# list of jensen shannon distances
sims = jensen_shannon(query, matrix)
# the top k positional index of the smallest Jensen Shannon distances
return sims.argsort()[:k]
xem chi tiết tại: utils.py
- Hàm
get_most_similar_documents()trả vềindexcủa cácdocumentstrong cơ sở dữ liệu của mình (bắt đầu từ 0 và tương ứng với index các hàng trong ma trậndocuments x topicsbên trên, đó cũng chính là lí do vì sao phải lưu giữ ma trận này lại). Với trường hợp códocumentmới được thêm vào cơ sở dữ liệu (1 bài viết mới trên Viblo), sau khi đã tính toán đượcvectorphân phối theotopicscủadocumentđó bằng methodtransformbên trên, các bạn tiến hành cập nhật ma trậndocuments x topicsbằng cách thêm 1 hàng vào cuối ma trận đó. Vậy là xong!
Kết quả
- Sau đây là một số kết quả khi chạy model. Về database thì mình sử dụng
MongoDB, web framework làFlask




- Khá ổn phải không nào =))
Kết luận
-
Trên đây là bài blog giới thiệu xây dựng 1 hệ gợi ý cơ bản cho website Viblo. Các bước tuần tự từ chuẩn bị dữ liệu, tiền xử lí dữ liệu và mô hình hóa bằng thuật toán LDA, hi vọng sẽ có ích cho những bạn quan tâm đến
Recommender Systemhay những bạn mới bắt đầu tiếp cận vớiMachine Learningnói chung. Nếu các bạn có bất kì thắc mắc nào hãy comment bên dưới hoặc tiến hành tạoIssuehayPull Requeststrên repo của mình nhé, mọi chi tiết xin liên hệ mình theo địa chỉ:phan.huy.hoang@framgia.com -
Github Link: https://github.com/huyhoang17/LDA_Viblo_Recommender_System
-
Nếu các bạn thấy hữu ích khi đọc bài viết của mình, hãy upvote và star cho repo của mình nhé! Cảm ơn mọi người đã đọc bài viết và hẹn gặp lại trong những bài blog tiếp theo!